[인공지능] Self Attention이란? Self Attention 핵심 아이디어 및 계산 과정
📌 Self Attention이란?

말그대로 자기 자신한테 Attention을 취함
it이 가르키는 것이 위의 문장에서 animal인 것 등을 컴퓨터가 알기 쉽도록 하기 위함
📌 Self Attention의 핵심 아이디어

Self Attention에서는 Query, Key, Value라는 3가지 변수 존재
Query - 의문, Key - 열쇠, Value - 값을 의미
물어보고, 키를 통해 최종 값을 얻는다고 생각하면 됨
예를들어, 512호에 들어가 슬리퍼를 가지고 오고자 할 때, “512호 예약자인데 어떻게 들어가나요?”라는 말이 Query, 이에 직원이 준 512호의 열쇠가 Key(Q와 K의 유사도 파악), 512호 내부에 존재하는 슬리퍼가 Value(유사한 만큼 V 가져오기)가 됨
Query, Key, Value의 시작 값이 동일
그러나 중간에 학습 weight W값에 의해 최종적인 Query, Key, Value가 생성
해당 Query, Key, Value의 연산을 통해 Attention Value Matrix를 구함
이를 통해 어떤 단어간의 상관관계가 있는 지 파악 가능
📌 Self Attention 계산 과정

[Scaled dot-product Attention]
Query와 Key 내적 (둘 사이의 연관성을 계산하기 위함)
이때, Query와 Key의 차원이 커지면
내적 값인 Attention score 또한 커지게 되어 학습에 어려워지므로
dk의 루트만큼 나누어주어 스케일링 작업 수행
이후 완성된 scaled dot-product attention을 정규화 및 보정을 위해
softmax 활성 함수를 거친 후 score행렬과 Value행렬을 내적해줌 (해당 유사도만큼 V를 가져오기 위함)
➡️ 최종적으로 Attention Value Matrix를 통해 어떤 단어간의 상관관계가 있는 지 파악 가능
📌 Self Attention 계산 과정 예시
“I am a student.” 라는 문장이 있다고 가정
“I”의 임베딩이 [1, 1, 1, 1]이라 하였을 때,
처음 “I”의 Query / Key / Value를 Qi, origial / Ki, origial / Vi, origial이라고 함
(위에서 설명한 바와 같이 한 symbol에 대한 초기 Q, K, V는 동일)
각 학습된 weight값이 WQ, WK, WV라고 할 때,
아래의 사진과 같이 dot product를 통해 Q, K, V 도출

이 Q, K, V값을 이용하여 Scaled Attention score(아직 v dot product X)를 구해본다면, 아래와 같이 1.5라는 값이 나옴
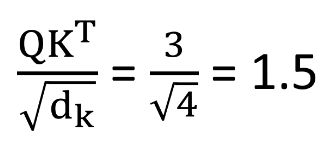
해당 과정을 “I”뿐만 아니라 모든 단어간에 취해주면, 아래와 같은 Matrix를 구할 수 있음

노란색 값은 가운데 자기 자신에 대한 Attention이므로 가장 크며,
초록색 부분을 보면 I와 Student 사이에 상관관계가 있다는 것을 확인할 수 있음
『
이해를 돕기 위해 단어 하나의 Attention을 구하는 과정을 설명하였으나,
실제로는 여러 단어를 아래와 같이 병렬처리하여 계산 수행 (연산속도 up)

』