[논문 리뷰] CNN 서베이 논문 : Recent Advances in Convolutional Neural Networks
📌 논문 링크
Recent Advances in Convolutional Neural Networks
In the last few years, deep learning has led to very good performance on a variety of problems, such as visual recognition, speech recognition and natural language processing. Among different types of deep neural networks, convolutional neural networks hav
arxiv.org
📌 Overview
Convolutional Neural Network의 발전에 대한 광범위한 조사를 제공함 ( ~ 2017 )
[ 📌 Introduction ]
CNN의 발전 및 문제점
전반적인 내용 소개
[ 📌 Basic CNN Components ]
CNN의 통상적인 구조 (Convolutional layer, Pooling layer, Fully-connected layer)
[ 📌 Improvements on CNNs ]
Convolutional layer, Pooling layer, Activation function, Loss function, Regularization, Optimization의 6가지 측면에서 CNN
의 주요 개선 사항 소개
[ 📌 Fast Processing of CNNs ]
적절한 시간 내에 네트워크를 트레이닝하는 다양한 방법론
[ 📌 Applications of CNNs ]
적용 및 활용방안
[ 📌 Conclusions and Outlook ]
전반적인 내용 정리
앞으로의 개선점 제시
📌 Abstract
Annotated data의 급증과 GPU 성능의 발달로 Convolutional Neural Networks에 대한 연구가 빠르게 성장하여 다양한 Task에서 SOTA(state-of-the-art)를 달성해옴
본 논문은 이러한 컨볼루션 신경망의 최신(2017 기준) 발전에 대한 광범위한 조사를 제공함
- Layer design, Activation function, Loss function, Regularization, Optimization, Fast computation을 포함한 다양한 측면에서 CNN의 개선 사항을 자세히 설명
- Computer vision, Speech and natural language processing분야에서 CNN의 다양한 응용 방법 소개
📌 Introduction
CNN(Convolutional Neural Network)은 생물의 자연스러운 시각적 인식 메커니즘(시각 피질의 세포가 수용 영역에서 빛을 감지하는 역할을 함)에서 영감을 얻어 현대적 프레임워크를 확립해옴
1990년대엔 위의 기초 메커니즘을 토대로 아래와 같은 신경망을 구현함
[ 💡 LeNet-5 ]
여러 계층을 가지며 역전파 알고리즘을 사용하여 훈련
원본 이미지의 effective representations를 얻을 수 있으므로 전처리를 거의 하지 않고 원시 픽셀에서 직접 시각적 패턴을 인식할 수 있었음
[ 💡 SIANN(Shift-invariant Artificial Neural Network) ]
Zhang 등의 병행 연구, 이미지에서 문자를 인식
그러나 당시에는 대규모 훈련데이터/GPU 성능이 부족하여 더 복잡한 문제를 수행할 수 없었음
2006년부터 심층 CNN 훈련시 직면하는 어려움을 극복하기 위해 많은 방법이 개발됨
[ 💡 AlexNet ]
LeNet-5와 유사하지만 더 깊은 구조를 지님
AlexNet의 성공으로 인해 성능 향상을 위한 많은 연구가 제안됨
(➡️ ZFNet, VGGNet, GoogleNet, ResNet의 4가지 연구가 대표적)
아키텍처의 진화에서 네트워크가 점점 더 깊어진다는 추세를 발견할 수 있음
(ILSVRC(2015)에서 우승한 ResNet은 AlexNet보다 약 20배, VGGNet보다 8배 더 깊음)
깊이를 증가할 경우 비선형성의 증가로 network는 목표 함수에 더 잘 근접할 수 있으며 더 나은 feature representation을 얻을 수 있음
[ 🚨 ]
그러나 깊어질수록 네트워크의 복잡성을 증가시켜 최적화하기 어렵고 과적합의 문제가 쉽게 발생하는 문제점 존재
이에 따라 해당 문제를 다양한 측면에서 다루기 위한 다양한 방법들을 제안하며 CNN은 발전함
이에 아래와 같은 내용을 다루며 CNN에 대해 알아가보고자 함
Basic CNN Components
Improvements on CNNs
Fast Processing of CNNs
Applications of CNNs
Conclusions and Outlook
아래 그림은 본 논문에서 다룰 CNN의 기본 구성 요소에 대한 개요를 보임
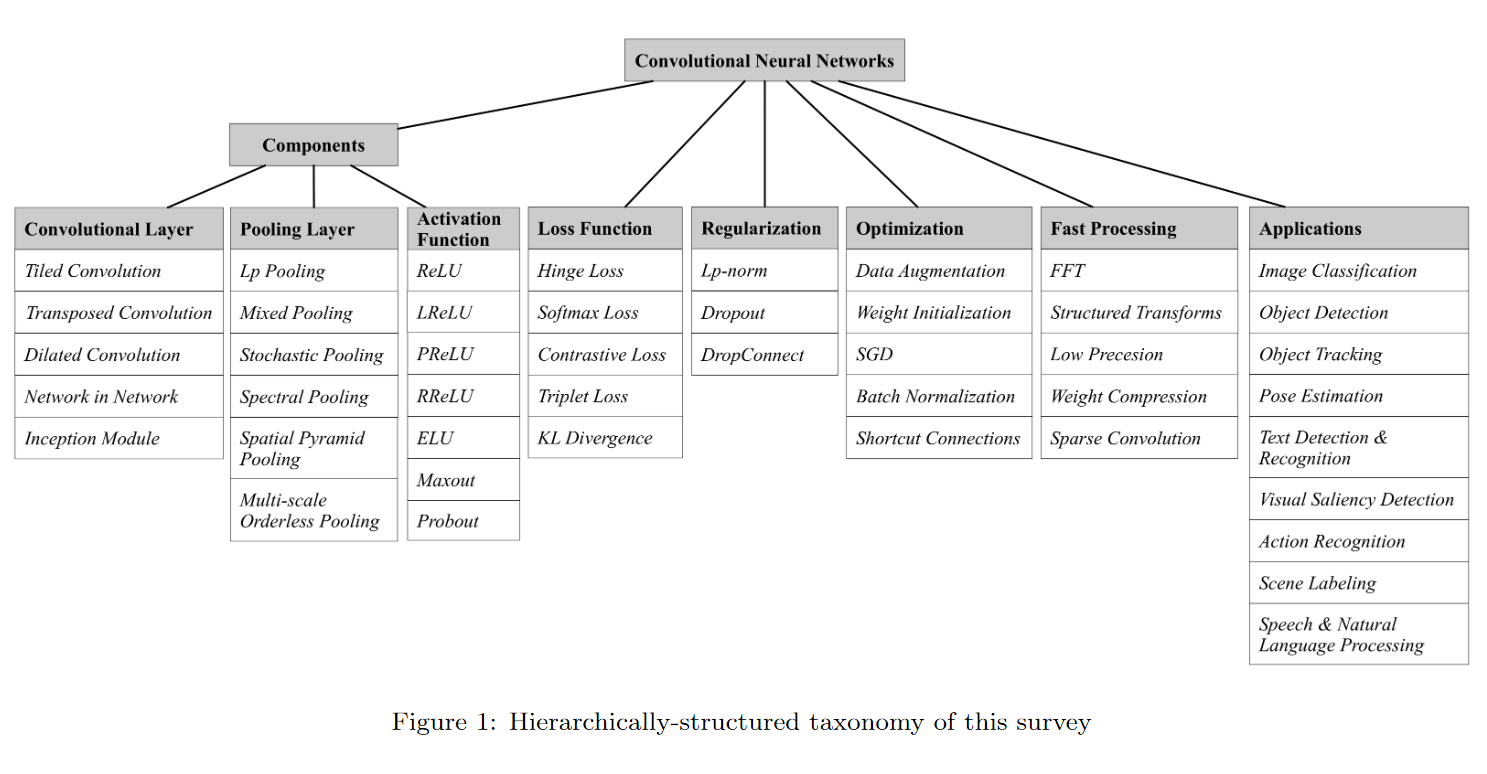
📌 Basic CNN Components
문헌에는 CNN 아키텍처의 다양한 번형이 있으나, 기본 구성 요소 대부분 동일
다음의 3개의 layer가 대표적인 기본 구성 요소
[ 💡 Convolutional Layer ]
목표 : 입력 데이터의 feature representations를 학습하는 것
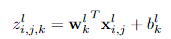
( w : weight / x : input patch / b : bias )
w는 k번째 feature map의 weight로써 l번째 layer의 모든 feature map을 산출하는데에 공유
weight sharing 방법론은 네트워크의 복잡성을 줄이고 네트워크를 학습하기 쉽게 함
위와 같은 과정을 통해 feature map을 산출함
이후 활성화함수로 CNN에 비선형성을 도입하기 위해 활성화함수를 거침
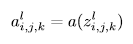
일반적으로 sigmoid, tanh, ReLU가 사용됨
[ 💡 Pooling Layer ]
목표 : shift-invariance를 획득하기 위한 feature map의 해상도 감소
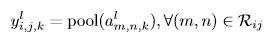
일반적으로 두개의 Conv layer 사이에 위치하며 average-pooling / max-pooling이 대표적
[ 💡 Fully-connected Layer ]
목표 : 고차원 추론 수행
1 x 1 Conv layer로 대체 가능하여 항상 필요한 층은 아님
마지막 층(output layer)에서 최종적으로 softmax, SVM 등을 사용하여 classification tasks 수행
이때, 다음과 같은 손실(Loss function)을 사용하여 최적화 수행
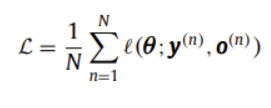
위 loss를 최소화하여 최적의 parameters를 찾아내고자 함
최적화 기법은 일반적으로 SGD 사용
『
- Convolutional layer : 이미지로부터 공간적 정보를 습득하여 Task에 따른 학습에 적절한 변수들로 구성된 feature map 생성
- Pooling layer : feature map의 해상도를 줄여 Shift-invariance 획득 및 계산량 감소
- Fully-connected layer : 위 과정을 통해 만들어진 변수들을 활용하여 최종 Task 계산 수행
CNN은 위 레이어들의 파라미터를 최적화해가며 최종 Task에 맞는 구조를 도출함
』
📌 Imporovement on CNNs
2012 AlexNet의 성공 이후 다양한 CNN의 개선 존재
해당 섹션에서는 Convolutional layer, Pooling layer, Activation function, Loss function, Regularization, Optimization의 6가지 측면에서 CNN의 주요 개선 사항을 설명하고자 함
[ 💡Convolutional Layer ]
representation ability를 목표로 아래와 같은 다양한 layer가 연구됨
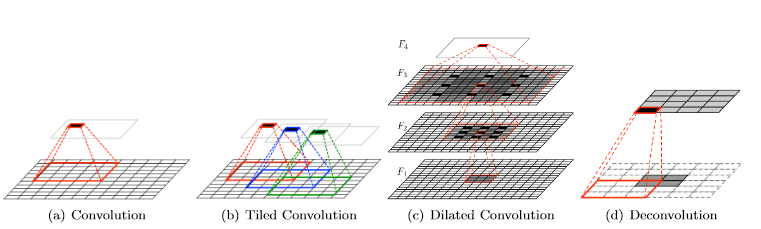
( Tiled Convolution )
회전 및 스케일 불변 기능을 학습하기 위한 multiples feature maps을 학습하는 것을 목표로 함
기존의 weight sharing 방법은 파라미터의 수를 급격하게 낮췄으나 invariance한 특성을 학습하는 데에 제한이 있었음
➡️ 동일한 레이어 내에서 별도의 독립된 convolution kernel을 두어 해결
위의 (b)에서 볼 수 있듯 k(가중치가 공유되는 거리를 제어)단위마다 convolution 적용
k가 1일 경우 기존의 convolution과 동일해지며 연구 결과 k=2일 때 가장 좋은 성능을 냄
기존 CNN보다 small time series 데이터셋에서 좋은 성능
( Transposed Convolution (Deconvolution) )
convolution의 역방향 전달로, deconvolution, fractionally strided convolution으로도 알려짐
여러 입력 활성화를 단일 활성화에 연결하는 기존 convolution과 달리, 단일 활성화를 여러 출력 활성화와 연결
위의 (d)는 unit stride와 제로패딩을 사용하여 4 x 4 입력에 대한 3 x 3 커널의 연산을 보여줌
➡️ 먼저 패딩을 사용하여 보폭 값만큼 입력을 업샘플링한 다음 업샘플링된 입력에 대해 컨볼루션 작업 수행
최근(2017 기준) visualization, recognition, localization, semantic segmentation, visual question answering, super-resolution 등에 널리 사용됨
( Dilated Convolution )
CNN의 발전으로 Convolutional layer에 하이퍼파라미터 하나를 더 추가
➡️ filter element 사이에 0을 끼워넣음으로써 receptive field를 늘리고 더 많은 relevant information을 다룰 수 있게 함
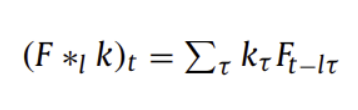
( dilation l / signal F / kernel k / size r )
위의 (c)는 3층의 dilated convolution layer를 보여주며 최근 scene segmentation, machine translation, speech synthesis, speech recognition 분야에서 좋은 성능을 보임
( Network in Network (NIN) )
Convolution layer의 linear filter를 작은 네트워크(mlpconv)로 대체
latent concepts(잠재 개념)의 보다 추상적인 표현에 representation을 근사하기 위함
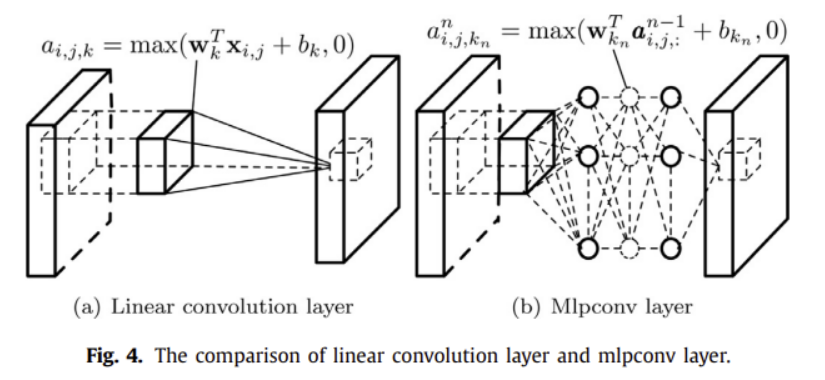
➡️ (a)에 비해 (b)가 더 적은 parameter를 사용하며 Overfitting 위험을 줄일 수 있음
( Inception module )
다양한 크기의 visual 패턴을 잡아내기 위해 다양한 크기의 filter를 사용하고 최적 sparse structure 근사
일반적으로 하나의 pooling layer와 다른 종류의 3가지 convolution 연산 포함
이때 3가지 convolution 연산은 1x1, 3x3, 5x5이며 이를 병렬적으로 사용하여 계산 복잡도를 증가시키지 않고 CNN의 깊이와 넓이를 증가시켜 차원을 축소할 수 있음
➡️ Inception module의 도움으로 파라미터 수가 급격하게 감소할 수 있었음
최근(2017 기준) 논문에서는 상대적으로 적당한 계산 복잡성에 고성능 네트워크 구조를 찾아내기 위해 representation size가 input에서 output으로 완만하게 감소하고 spatial aggregation이 표현 손실 없이 저차원 임베딩되어 수행해야 한다고 제안함
『
즉, 공간 정보를 잘 활용하여 잠재개념을 효과적으로 표현하면서도
네트워크 복잡성을 낮추고 과적합 문제를 방지하는 방향으로 Convolutional layer는 발전해옴
』
[ 💡 Pooling Layer ]
Convolutional layer간의 연결 수를 줄여 계산 부담을 줄이기 위해 아래와 같은 다양한 layer가 연구됨
( Lp Pooling )
max pooling보다 일반화 성능이 좋음
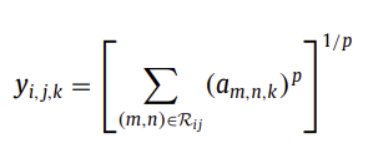
p가 1이면 average pooling, p가 inf이면 max pooling과 동일
( Mixed Pooling )
Random Dropout과 Dropconnect에 영감을 받은 방식
max pooling + average pooling
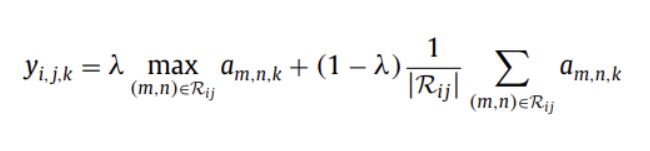
람다는 0과 1 사이의 임의의 값으로,
average pooling과 max pooling의 비율을 정함 (순정파 때 결정)
Overfitting 문제에 적용하기 좋음
average, max pooling 방법보다 성능 우수
( Stochastic Pooling )
Dropout에 영감을 받은 방식
다변량정규분포에 따르도록 랜덤하게 activation을 선택
p의 확률적으로 선택
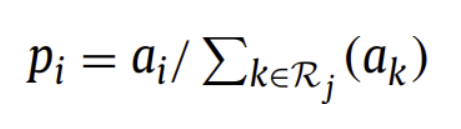
max pooling에 비해 Overfitting 방지할 수 있음
( Spectral Pooling )
주파수 영역에서 input의 representation을 잘라내어 차원 축소 수행
m x m의 feature map을 h x w 크기의 feature map으로 변환하기 위해 DFT를 계산하고, 중심에 h x w 크기의 주파수만 남기고 잘라낸 후 inverse DFT를 거쳐 다시 spatial domain으로 근사
max pooling에 비해 동일한 출력 차원에 대해 더 많은 정보 보존
다른 pooling 기법들에 비해 급격한 차원 축소에서 자유로움
행렬 계산으로 수행되어 계산량 낮음
( Spatial Pyramid Pooling )
input size와 관계없이 고정된 길이의 representation 생성
SPP Pool은 이미지 크기에 비례하는 크기를 가진 local spatial bin에 입력 feature map을 입력하여 bin의 수를 고정
(sliding window 크기에 따라 output의 크기가 결정되는 방식과 다름)
( Multi-scale Orderless Pooling )
전체 이미지와 여러 스케일의 local patch 몯로부터 activation feature 추출
전체 이미지에서 activation을 추출하는 것은 기존 CNN과 동일 (공간정보 추출 목적)
local patch로부터 activation을 추출하는 것은 더 local하고 fine-grained한 세부 정보를 획득하는 역할을 수행
『
Pooling layer는 Convolutional layer에서 추출한 공간 정보 등을 간직하면서도
네트워크의 복잡도(계산량)를 줄이기 위해 다양한 방법으로 발전해옴
』
[ 💡 Activation Function ]
Activation function의 적절한 기능은 CNN의 성능을 크게 향상시킴
최근(2017 기준) CNN에서 사용되는 활성화함수는 아래와 같이 존재
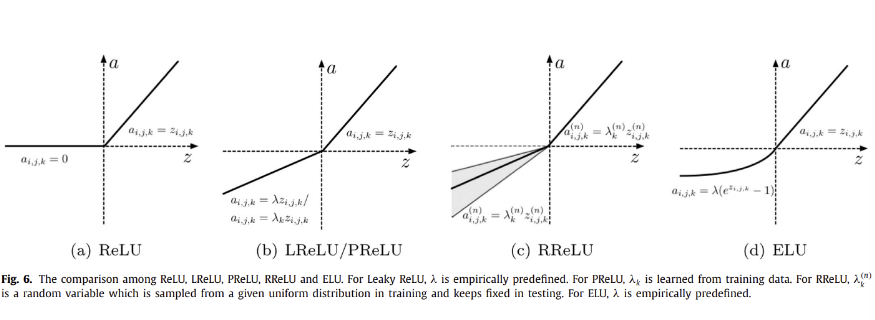
( ReLU )
음수 값을 가지면 0으로, 양수 값을 가지면 자기 자신을 내뱉는 활성화함수
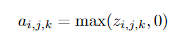
max연산만을 사용하여 상당히 빠르고, 네트워크가 희소 표현을 쉽게 얻을 수 있도록 함
0에서의 ReLU의 불연속성이 역전파 기능을 저하시킬 수 있음에도 많은 연구에서 Sigmoid, tanh 활성화 함수보다 더 잘 작동한 것으로 나타남
( Leaky ReLU )
양수 값을 가지면 자기 자신을, 음수 값을 가지면 아주 작은 파라미터 람다를 곱한 값을 내뱉는 활성화함수
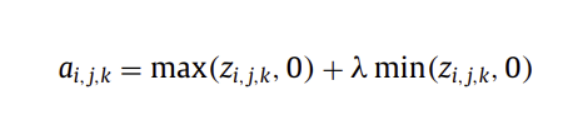
초기 음수일 경우 활성화되지 않을 수 있는 ReLU의 단점 극복
( Parametric ReLU )
Leaky ReLU의 고정람다 대신, 정확도를 향상시키기 위해 학습 파라미터를 사용하여
양수 값을 가지면 자기 자신을, 음수 값을 가지면 아주 작은 파라미터 람다를 곱한 값을 내뱉는 활성화함수
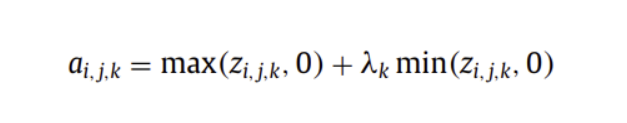
Overfitting 위험이 추가되지 않으며 계산량 추가 또한 없음
( Randomized ReLU )
양수 값을 가지면 자기 자신을, 음수 값을 가지면 uniform 분포로부터 랜덤하게 샘플된 파라미터를 사용하여 값을 내뱉는 활성화함수
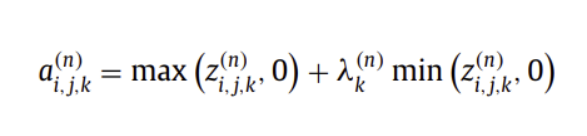
랜덤한 특성 덕분에 Overfitting을 줄일 수 있음
RReLU를 제안한 연구자에 따르면 ReLU, LReLU, PReLU 보다도 RReLU가 좋은 성능을 보인다고 함
( ELU )
양수 값을 가지면 자기 자신을, 음수 값을 빠른 학습에 유리한 분포의 값을 내뱉는 활성화함수
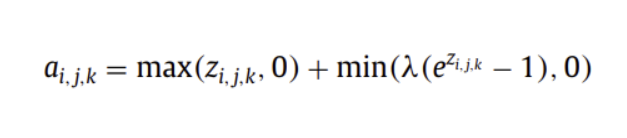
빠른 학습에 유리하며 노이즈에 견고함
( Maxout )
k개의 채널의 feature map이 있다면 그 중 가장 큰 값을 내뱉는 활성화 함수
ReLU의 강점을 이용하며 동시에 Dropout의 효과를 볼 수 있음
( Probout )
k개의 채널의 feature map이 있다면 그 중 가장 큰 값을 내뱉는 maxout의 방법을 확률적으로 활용
바람직한 특성을 보존 ↔ 불변성 특징 향상 사이의 균형을 이룰 수 있음
그러나 확률 계산으로 인해 maxout보다 계산량이 늘어남
『
전반적으로 기울기 소멸 문제와 오버피팅 문제를 방지하기 위해
기울기가 너무 작지 않으면서, 0이 아닌 방향으로 노력해옴
』
[ 💡 Loss Function ]
올바른 최적화를 위해 적절한 손실함수를 결정할 필요성 존재
아래와 같은 네 가지 대표적 손실이 활용되어옴
( Hinge Loss )
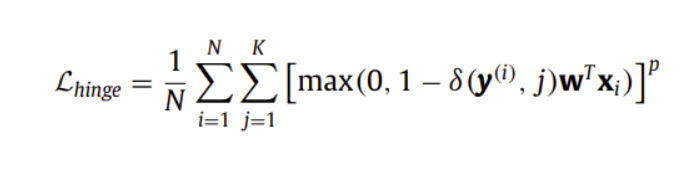
w는 weight, y는 class label(1~K)
맞췄을 때 1, 틀렸을 때 -1을 내뱉음
p=1이면 Hinge-Loss (L1 loss) / p=2이면 Squared Hinge-Loss (L2 loss)
일반적으로 Support Vector Machine(SVM)과 같은 large margin classifiers를 훈련하는 데에 사용
( Softmax Loss )
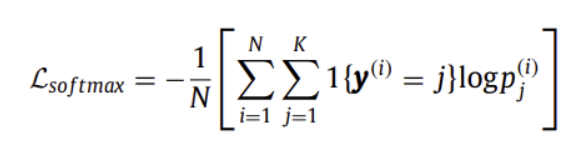
multinomial logistic loss + softmax
0과 1 사이의 값으로 확률로써 해석 가능하도록 내뱉음
상대적으로 어려운 학습 목표를 규정하는데 도움이 되고 Overfitting을 효과적으로 피할 수 있음
( Contrastive Loss )
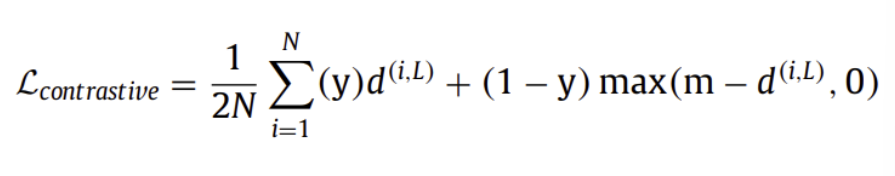
일반적으로 일치 또는 비일치로 분류된 데이터 pair간의 similarity를 학습하기 위한 weakly supervised scheme의 siamese network를 학습하는 데에 사용
모든 pair로 네트워크를 fine-tuning할 때 급격한 성능 감소
(비일치 pair의 경우에만 fine-tuning시 좋은 성능을 보이기 때문에 일치하는 pair를 잘 다루는 것이 중요)
( Triplet Loss )
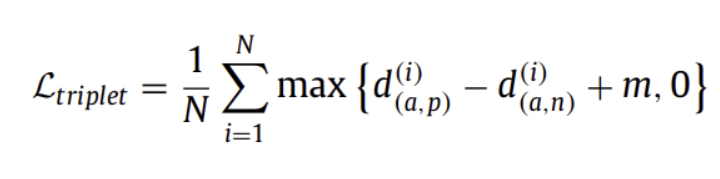
anchor와 positive 간의 거리를 최소화하고, anchor와 negative 간의 거리는 최대화하는 목적
(anchor instance, positive instance, negative instance의 세가지 유닛 고려)
( Kullback-Leibler Divergence )
같은 discrete variable x를 공유하는 두 개의 확률분포 p(x)와 q(x) 사이의 차이를 계산
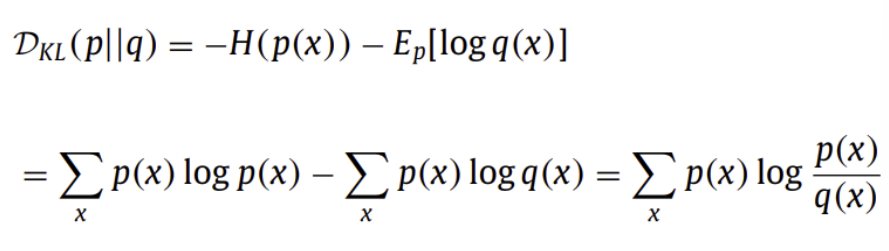
다양한 Autoencoders (AE)의 목적 함수 속 information loss의 measure로 널리 사용되어 옴
KLD의 symmetrical form인 Jensen-Shannon Divergence (JSD)는 아래와 같으며 Generative Adversarial Networks (GANs)에 일반적으로 사용됨
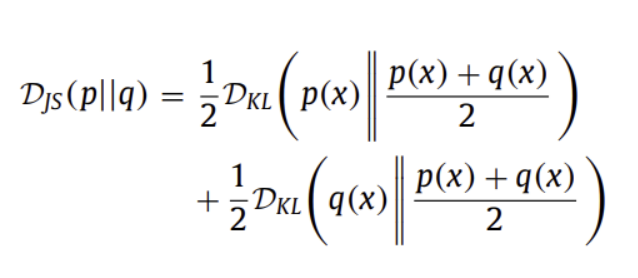
『
최적화의 척도이니 만큼, 분류 Task에서 보다 의미있는 결과를 내기 위해 다양한 연구가 진행되어옴
』
[ 💡 Regularization ]
deep CNN에서 무시할 수 없는 Overfitting문제를 효과적으로 줄일 수 있는 하나의 방법으로,
아래와 같은 연구가 진행되어옴
( Lp-norm Regularization )
모델 복잡성에 패널티를 주는 additional term을 추가하여 loss 함수를 수정
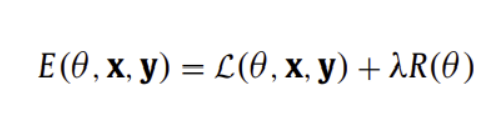
일반적인 loss function에 추가하여 regularized loss로 표현
Lp-norm regularization은 아래와 같은 additional term을 사용함
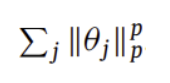
p가 1 이상이면 Lp-norm은 convex하여 최적화가 쉬워짐
p가 2일 때 일반적으로 weight decay로 불림
( Dropout )
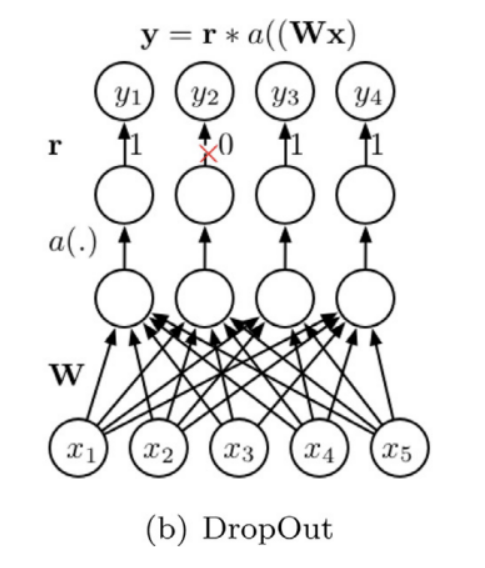
위와 같은 방식으로 노드의 확률적 비활성화를 통해 Overfitting을 줄이는 데에 효과적
Dropout은 네트워크가 특정 뉴런에 너무 의존적으로 학습되지 않도록 방지하고,
특정 정보의 부재로 인해 더욱 정확해질 수 있도록 강제
fast Dropout / adaptive Dropout / Dropout before 1 x 1 conv layer / spatial Dropout등의 연구가 진행되어옴
( Dropconnect )
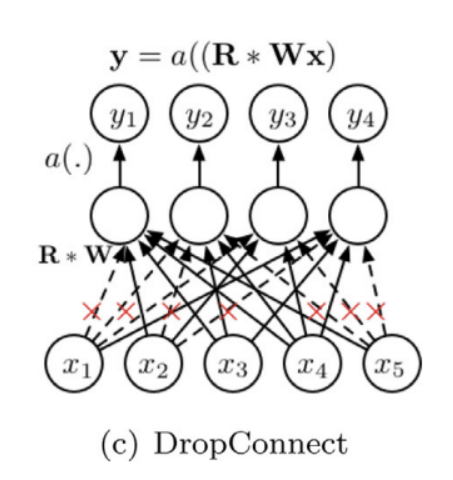
Dropout을 한 스텝 일찍 적용하는 아이디어로, 뉴런의 output을 랜덤하게 비활성화시키는 것이 아니라 weight를 랜덤하게 0으로 두어 학습이 되지 않도록 함
『
2D 이미지를 다루고 층이 많아지는 CNN에서 Overfitting 문제는 지속적으로 발생
이를 방지하기 위한 다양한 Regularization기법들이 연구되어옴
』
[ 💡 Optimization ]
CNN 네트워크를 최적화하는 기술들에 대해 연구되어옴
( Data Augmentation )
[ 🚨 ]
deep CNN은 많은 양의 데이터에 의존하는 경향이 큼
➡️ 데이터 증강으로 해결
이때, 데이터의 본질을 바꾸지 않고 새로운 데이터로 변형하는 것이 중요
대표적으로 sampling, mirroring, rotating 및 다양한 photometric transformations 존재
( Weight Initialization )
Deep CNN의 복잡한 로스 함수에서의 빠른 수렴 및 기울기 소멸 문제 완화를 위하여 적절한 가중치 초기화 필요
bias 변수는 0이로 초기화 될지라도, 가중치 매개변수들은 주의 깊게 초기화되어야 함
zero-mean Gaussian distribution with standard deviation 0.01, Xavier등의 방법 존재
( Stochastic Gradient Descent )
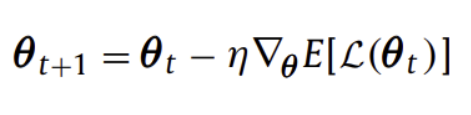
gradient descent 알고리즘들은 위와 같이 매개변수를 갱신해옴
여기서 expectation 값을 손실함수의 기울기로 바꾼 것이 SGD
SGD는 적절한 학습률을 설정하는 것이 어려우며, 이에 특정 값으로 정해놓고 학습이 진행되며 점차 낮추는 방법 또한 존재 (그러나 수렴을 하지 못할 수 있음)
( Batch Normalization )
[ 🚨 ]
global data normalization은 모든 데이터를 평균 0, 분산 1의 분포를 따르도록 변형하므로 깊은 네트워크를 흘러감에 따라 값을 잃게 되고 정확도가 낮아짐
➡️ mini batch 이후마다 평균 0, 분산 1의 분포를 따르도록 변형
Batch Normalization은 아래와 같은 많은 장점을 지님
internal covariant shift를 줄임
초기값 의존도를 낮추어 gradient flow를 원활하게 함
devergence 위험 없이 높은 학습률 사용 가능
Dropout의 필요성을 낮춤
sturated model에 문제 없이 saturating nonlinear activation function 사용 가능
( Shortcut Connections )
[ 🚨 ]
deep CNN의 기울기 소멸 문제는 Initialization 및 Batch Normalization을 통해 완화될 수 있음
해당 방법들이 성공적으로 Overfitting을 막을 수는 있으나 최적화 성능을 떨어뜨려 오히려 shallow 네트워크보다 안 좋은 성능을 가져올 수도 있음
이러한 Optimization 문제를 degradation 문제라고 함
➡️ LSTM에 영감을 받아 임의적 깊이를 사용하여 최적화를 가능하게 하는 highway network가 제안됨
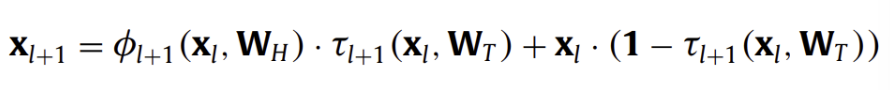
해당 매커니즘은 input과 output의 크기를 같도록 강제하고, 수십 수백개의 layer들이 효과적으로 학습될 수 있도록 함
해당 아이디어를 사용하여 큰 성공을 거둔 대표적 모델이 Residual Nets(ResNet)
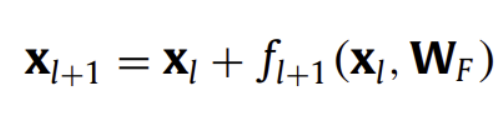
위와 같은 수식으로 shortcut connections을 수행하였고, 그 결과 굉장히 깊은 layers를 사용하면서도 안정적으로 optimize하는 것이 가능해짐
(f : Convolution, BN, ReLU, Pooling 등)
『
깊고 복잡한 네트워크인 CNN은 복잡한 loss function으로 최적화가 쉽지 않음
이에 다른 문제점을 발생시키지 않으면서 적절히 최적화할 수 있는 방법들이 연구되어 옴
』
📌 Fast Processing of CNNs
컴퓨터 비전 및 기계 학습의 작업의 과제가 증가함에 따라 심층 신경망 모델은 점점 더 복잡해짐
이러한 모델은 과적합을 방지하기 위해 훈련에 많은 데이터가 필요함
이에, 적절한(가능한) 시간 내에 네트워크를 트레이닝하는 방법과 같은 새로운 과제도 제시됨
[ 💡 FFT ]
FFT를 사용한 푸리에 영역에서의 컨볼루션 연산 수행
[ 💡 Structured Transforms ]
적절한 인수분해를 적용한 시간복잡도 감소
[ 💡 Low Precision ]
효율적인 계산을 위한 매개변수의 중복 정보 포함(중복성) 감소
[ 💡 Weight Compression ]
Vector Quantization, pruning, hashing등의 매개변수 줄이기
[ 💡 Sparse Convolution ]
Convolution layer의 가중치 희소화 (sparsify)
📌 Applications of CNNs
CNN은 지금껏 다양한 task에서 활용되어 왔으며, 아래와 같은 많은 분야에서 깊게 사용되어 옴
- image classification
- object detection
- object tracking
- pose estimation
- text detection
- visual saliency detection
- action recognition
- scene labeling
- speech
- natural language processing
📌 Conclusions and Outlook
레이어 디자인, 활성화 함수, 손실 함수, 정규화, 최적화 및 빠른 계산과 같은 다양한 측면에서 CNN의 개선 사항을 알아봄
그러나 몇가지의 개선사항 존재
- CNN이 점점 더 깊어짐에 따라 large-scale dataset과 massive compution power가 필요하지만 labeling이 된 대규모 데이터를 구하는 것은 쉽지 않기에 비지도학습 방식의 CNN을 고민해보아야 함
- CNN을 새로운 task에 적용할 때 적절한 hyperparameter들을 고안해야 함
- CNN은 현재 좋은 성능으로 적용하고 있지만 설명 가능성이 낮음
📌 느낀 점
CNN(Convolutional Neural Network)과 MLP(Multi-Layer Perceptron)와의 차이를 직접 확인해보는 소규모 프로젝트를 진행해보며 기존 MLP의 문제점과 이를 해결하기 위한 CNN의 기초적인 구조를 알아보았음
CNN의 공간적 구조를 데이터에 지닐 수 있다는 장점에 감탄하여 발전된 CNN의 양상에 호기심이 생김
이에 CNN의 문제점 및 해결을 위한 발전들이 계속하여 있을 것임을 전제로, CNN 기초부터 나아가는 발전의 흐름을 자세히 알아보고자 본 서베이 논문을 택하여 읽기로 결심함
『
CNN의 발전 동향 및 기초 지식를 얻고 싶은 목적에 따라 Section 2 / 3에 해당하는 내용은 자세히 다루고, Section 4 / 5의 경우 종류 파악 및 내용 이해를 목표로 하였음
』
본 논문을 읽어보며, CNN의 기초 지식과 전반적인 역사 및 응용 방법을 이해할 수 있었음
특히나 Section 2, 3에 집중한 만큼 CNN이 Conv, Pool, FL의 구조로 구성되어있다는 사실과
점차 깊어지는 경향을 보이는 CNN에서 발생할 수 있는 문제점(Overfitting, Vanishing Gradient 등) 및 이를 해결하기 위한 다양한 방법들을 흐름에 따라 접하고 공부해볼 수 있었음
공부하는 과정에서 CNN이 깊고 계산량이 많다는 것을 알 수 있었는데, Section 6, Conclusion에서 언급한 저자의 말이 인상깊었음
깊은 네트워크이며 계산량이 많을 수록 정확히 어째서 성능이 강화된건지에 대한 설명 가능성이 낮다는 사실이 흥미로웠으며, downstream의 task에 활용을 하기 위해서는 이 설명가능성을 높여야 사용자의 신뢰있는 활용이 가능하지 않을까 싶음
또한 저자는 당시(2017 기준) 비지도학습 방식의 CNN을 고민해보아야 한다고 언급하였는데, 최근(2024 기준) 라벨링되지 않은 데이터를 활용한 self-supervised learning이 활발히 연구되고 있는 것이 신기했음
마지막으로, 2017년 정리된 서베이논문을 읽어본 이유는 최신 논문에서는 Transformer의 등장으로 CNN 기초 내용의 부재를 느꼈기 때문인데 이 Transformer의 등장에 따른 CNN의 발전 및 2017 이후의 CNN의 동향 또한 차차 알아가보고 싶다는 생각이 듦