[논문 리뷰] (22’ECCV) Visual Prompt Tuning
📌 논문 원문
Visual Prompt Tuning
The current modus operandi in adapting pre-trained models involves updating all the backbone parameters, ie, full fine-tuning. This paper introduces Visual Prompt Tuning (VPT) as an efficient and effective alternative to full fine-tuning for large-scale Tr
arxiv.org
📌 Overview
최근 GPT 계열의 모델과 같이 대규모 데이터와 대규모 모델을 활용한 딥러닝 연구가 많아짐
[ 🚨 ]
엔디비아나 구글과 같이 엄청난 컴퓨팅 파워를 가지고 있는 대기업이 아닌 일반인들은 Pretrain된 모델을 Fine-tuning하는 것도 어려운 상황에 이르름
이에 다양한 활용 방안이 나왔으나, 학습 파라미터와 성능의 trade-off 문제 발생
➡️ 비전 분야에서 대규모 Transformer 모델을 효율적으로 활용하기 위한 새로운 fine-tuning 방법인 Visual Prompt Tuning (VPT) 제시

기존의 연구에 영감을 받아, 백본 모델은 동결시키되 학습 가능한 소수의 파라미터, 프롬프트를 추가하며 head와 함께 학습
기존의 fine-tuning 방법보다 더 적은 양의 학습 가능한 매개변수를 도입하여 모델 성능을 향상시키는 방법
NLP 분야에서 먼저 Prompt Tuning이 연구되고 있었는데, 이를 CV 분야에서 활용하는 방법을 연구함
📌 Abstract
사전 훈련된 모델을 적용하는 현재 작업 방식에는 모든 백본 매개변수 업데이트, 즉 전체 미세 조정이 포함됨 (→ 너무 방대한 모델의 경우 어려움)
본 논문에서는 비전의 대규모 Transformer 모델에 대한 전체 미세 조정에 대한 효율적이고 효과적인 대안으로 VPT(Visual Prompt Tuning)를 제안
VPT는 대규모 언어 모델을 효율적으로 조정하는 최근의 발전에서 영감을 얻어 모델 백본을 고정된 상태로 유지하면서 입력 공간에 훈련 가능한 매개변수를 소량(모델 매개변수의 1% 미만)만 도입
다양한 다운스트림 인식 작업에 대한 광범위한 실험을 통해 VPT가 다른 매개변수 효율적인 튜닝 프로토콜에 비해 상당한 성능 향상을 달성한다는 것을 보여줌
VPT는 모델 용량과 훈련 데이터 규모 전반에 걸쳐 많은 경우에 완전한 미세 조정보다 성능이 뛰어나면서도 작업당 저장 비용을 절감함
📌 Introduction
대규모 데이터, 원시 데이터에 대해 사전 훈련된 대규모 기반 모델이 등장 (성공 사례)
그러나 이를 활용하기 위한 가장 좋은 방법은 사전 훈련된 모델의 full fine-tuning인데, 현실적으로 비용이 많이 들고 실행되지 않는 경우도 존재
이에 비용을 줄이려는 많은 노력이 있었으나, full fine-tuning에 비해 성능이 좋지 못함
이에 효과성, 효율성 측면에서 대규모 사전 훈련된 Transformer를 다운스트림 작업에 적용하는 방법을 찾고자 함
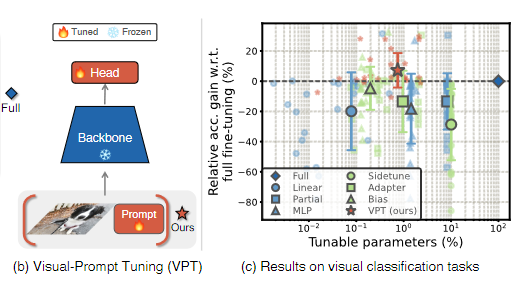
(b)
사전 훈련된 Transformer 자체를 변경하거나 미세 조정하는 대신 Transformer에 대한 입력을 수정함
다운스트림 훈련 중에 사전 훈련된 Transformer 백본 전체를 동결하면서 입력 공간에 소량의 작업별 학습 가능한 매개변수만 도입
실제로 이러한 추가 매개변수는 단순히 각 Transformer 레이어의 입력 시퀀스 앞에 추가되고 미세 조정 중에 선형 헤드와 함께 학습
(c)
사전 훈련된 ViT 백본을 사용하여 다양한 도메인에 걸쳐 있는 24개 다운스트림 인식 작업에서 VPT는 다른 모든 전이 학습 기준을 능가하며 20개 사례에서 전체 미세 조정을 능가하는 동시에 훨씬 적은 수의 매개변수(백본 매개변수의 1% 미만)만을 저장하는 이점을 유지
VPT는 특히 제한된 데이터 체제에서 효과적이며 데이터 규모 전반에 걸쳐 이점을 유지함
VPT는 다양한 Transformer 규모 및 설계(ViTBase/Large/Huge, Swin)에서 경쟁력이 있음
최종적으로 VPT가 비전 백본을 적응시키는 가장 효과적인 방법 중 하나임을 시사하고자 함
『
대규모 사전 훈련된 Transformer를 다운스트림 작업에 적용하는 효과적인 방법을 찾아보자
(근데 이제 컴퓨팅 비용이 적게들고 성능은 잘 나오는 … )
』
📌 Related Work
[ 💡 Transformer ]
NLP에서 큰 성공을 거두었으며 다양한 task에서 SOTA 달성
최근 self-supervised pre-training methods에도 널리 사용되고 있음
ConvNet에 비해 뛰어난 성능과 훨씬 더 큰 규모를 고려할 때,
Transformer를 다양한 비전 작업에 효율적으로 적용하는 것이 Computer Vision 분야에서 중요
본 논문에서 제안한 VPT는 Transformer를 활용한 유망한 경로를 제공
[ 💡 Transfer Learning ]
vision tasks에 대해 transfer learning이 광범위하게 연구되었으며 side tuning, residual adapter, bias tuning 등 다양한 기술이 도입됨
Transformer의 vision 적용에 대해서는 상대적으로 관심이 없었으며, 앞서 언급한 방법이 Transformer 아키텍쳐에 관해 얼마나 잘 수행되는 지 잘 알려지지 않음
사전 훈련된 대규모 LM(Transformer based Language Models)의 우세를 고려하여 다양한 다운스트림에 대해 LM을 효율적으로 미세 조정하기 위한 많은 접근 방식이 제안됨
NLP 작업 중 Adapters와 BitFit라는 두 가지 대표적인 방법에 중점을 둠
Adapters는 각 Transformer 레이어 내부에 추가 경량 모듈을 삽입
BitFit은 새로운 모듈을 삽입하는 대신 ConvNet을 미세 조정할 때 바이어스 항을 업데이트하고 나머지 백본 매개변수를 동결할 것을 제안하였으며, Transformers에 적용하여 LM 튜닝에 대한 효율성을 검증
본 연구는 NLP에서의 이들과 비교하여 CV 작업에 Transformer 모델을 적용하는 데 향상된 성능을 제공한다는 것을 보여줌
[ 💡 Prompting ]
Prompting은 원래 사전 훈련된 LM이 Task를 "이해"할 수 있도록 입력 텍스트에 언어 지침을 추가하는 것을 의미함
수동으로 선택한 프롬프트를 사용하면 GPT-3은 few-shot 또는 zero-shot 설정에서도 다운스트림 전이 학습 작업에 대한 강력한 일반화를 보여줌
더 나은 프롬프트 텍스트를 구성하기 위해 최근 연구에서는 프롬프트를 작업별 연속 벡터로 처리하고 미세 조정 중 그라디언트를 통해 직접 최적화하는 것을 제안
Prompt Tuning을 하게 될 경우 전체 미세 조정과 비교할 때 비슷한 성능을 달성하지만 매개변수 저장 공간이 1000배 적음
최근 Vision 언어 모델에도 프롬프트가 적용되었지만 프롬프트는 여전히 텍스트 인코더의 입력으로 제한됨
Vision과 Text양식의 차이로 인해 이 논문에서는 동일한 방법을 이미지 인코더에 성공적으로 적용할 수 있는지 알아봄
(지금까지와 달리 프롬프트를 텍스트 인코더가 아닌 이미지 인코더에서 활용해보자 !)
본 논문은 이 문제를 해결하고 여러 도메인과 백본 아키텍처에 걸쳐 여러 종류의 인식 작업을 포괄하는 광범위한 실험을 통해 시각적 프롬프트의 일반성과 타당성을 조사한 첫 번째 작업임
[ VPT 개요 ]

본 논문에서는 두 가지 변형을 탐구함
(a)
각 Transformer 인코더 레이어의 입력(VPT-deep)에 학습 가능한 매개변수 세트를 추가
(b)
첫 번째 레이어의 입력(VPTshallow)에만 프롬프트 매개변수를 삽입
다운스트림 작업에 대한 훈련 중에는 프롬프트 및 선형 헤드의 매개변수만 업데이트되고 전체 Transformer 인코더는 동결
『
참고해볼 사전 기능들을 알아보자
- Transformer 를 활용해보자
- 사전에 NLP에서 대규모 사전 훈련된 Transformer를 Transfer Learning하던 연구들을 참고하여 백본 매개변수를 동결하고 미세 조정시 바이어스 항을 업데이트하는 방법을 CV에서도 활용해보자
- 사전에 NLP에서 매개 변수 저장 공간을 크게 줄인 Prompt Tuning의 방법을 참고하여 CV에서도 가능한지 알아보자 (이미지 - 자연어간의 모달리티 차이가 존재하기 때문에, 이미지에서도 유효할지 검증해보자)
』
📌 Approach
large pre-trained vision Transformer 모델을 활용하기 위해 VPT 제안
VPT는 Transformer의 입력 공간에 학습 가능한 소수의 매개변수를 주입하고 다운스트림 훈련 단계에서 백본을 고정된 상태로 유지
[ 💡 Preliminaries ]
( Vit 배경 지식 )
N개의 레이어가 있는 일반 Vision Transformer(ViT)의 경우 입력 이미지는 m개의 고정 크기 패치로 나뉨

h, w는 이미지 패치의 높이와 너비를 의미
이후 각 패치는 먼저 positional encoding을 사용하여 d차원 잠재 공간에 삽입
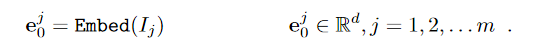
Ei = {ej i ∈ Rd | j ∈ N, 1 ≤ j ≤ m}는 패치된 이미지를 나타냄
i+1번째 Transformer layer(Li+1)의 입력으로 Ei 사용 (이미지 0 → 레이어 1의 인풋)
추가 학습 가능한 분류 토큰([CLS])과 함께 전체 ViT는 다음과 같이 공식화됨

xi ∈ Rd(d차원)는 Li+1의 입력 공간에 [CLS]가 포함된 것을 나타냄
[·, ·]는 시퀀스 길이 차원에서의 스택 및 연결을 나타냄
즉, [xi, Ei] ∈ R(1+m)×d (1+를 해주는 이유가 [CLS], Xi)
각 계층 Li는 LayerNorm 및 residual connection,
MSA(Multiheaded Self-Attention) 및 FFN(Feed-Forward Networks)으로 구성
neural classification head는 최종 레이어의
‘[CLS] 임베딩 Xn’을 예측된 클래스 확률 분포 ‘y’에 매핑하는 데 사용
( 고정 CLS, 이를 예측하는 최종 매핑 부분의 head 학습 )
『
ViT 모델을 활용하기 위한 배경 지식의 이해
기존의 Transformer를 최대한 그대로 사용하여 확장 가능한 NLP Transformer 아키텍처의 효율적 구현을 거의 즉각적으로 사용
이에 이미지를 Patch로 분할(Patch 임베딩) 후 Sequence로 입력하며, Patchify된 이미지의 위치를 파악하기 이해 Position 임베딩 수행
이후 Transformer 인코더에 넣어 Transformer 기반 이미지 분류가 가능하도록 함
』
[ 💡 Visual-Prompt Tuning(VPT) ]
사전 훈련된 Transformer 모델이 주어지면 Embed 레이어 뒤의 입력 공간에 차원 d의 p개의 연속 임베딩 세트, 즉 프롬프트를 도입
fine-tuning 중에는 작업별 프롬프트만 업데이트되고 Transformer 백본은 고정된 상태로 유지
Transformer 레이어의 수에 따라 VPT-shallow, VPT-deep의 두가지 변형 활용
( VPT-Shallow )
첫 번째 Transformer 레이어 L1의 입력공간에만 프롬프트 삽입
각 프롬프트 토큰은 학습 가능한 d차원 벡터
아래와 같이 p개의 프롬프트 모음 P 존재
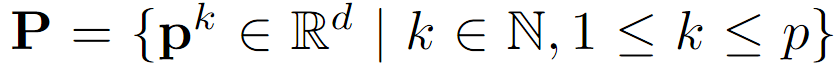
Shallow-prompted ViT는 아래와 같이 수식화

Zi ∈ Rp×d는 i번째 Transformer 레이어에서 계산된 features (promt의 Layer 거친 결과)

(토큰, 프롬프트, 이미지의 차원으로 구성)
붉은 색과 푸른 색 표시는 각각 학습 가능한 매개변수와 고정된 매개변수를 나타냄
붉은색은 학습 가능한 매개변수를 (Tuned)
푸른 색은 고정된 매개변수를 나타냄 (Frozen)
특히 ViT의 경우 Xn(토큰)은 Positional encoding 후에 삽입되므로 프롬프트 위치에 대해 변하지 않음
예를 들어 [x0, P, E0] 및 [x0, E0, P]는 수학적으로 동일 (VPT-Deep도 동일)
( VPT-Deep )
모든 Transformer 레이어의 입력 공간에 프롬프트 삽입
(i+1)번째 레이어 Li+1의 경우 학습 가능한 입력 프롬프트 모음을 아래와 같이 정의

Deep-prompted ViT는 아래와 같이 수식화

(+ 위에서 처음 뿐만 아니라 모든 레이어로 확장되었다고 생각하기)
( Storing Visual Prompts )
VPT는 여러 다운스트림 작업이 있는 경우 유용함
각 작업에 대해 학습된 프롬프트와 분류 헤드만 저장하고 사전 훈련된 Transformer 모델의 원본을 재사용하여 저장 비용 크게 절감
예를 들어, 8600만(M) 매개변수와 d = 768인 ViT-Base가 주어질 경우,
50 Shallow promts : p × d = 50 × 768 = 0.038M
Deep prompts : N × p × d = 0.46M
각 VPT는 위와 같은 매개변수를 생성
이는 전체 ViT-Base 매개변수의 각각 0.04%와 0.53%로 매우 낮음
『
최종적으로 VPT란,
Transformer의 입력 공간에 학습 가능한 소수의 매개변수를 주입하고 다운스트림 훈련 단계에서 백본을 고정된 상태로 유지함
(맨 앞의 레이어의 입력에만 prompt 추가하는 shallow, 모든 레이어의 입력에 prompt 추가하는 deep VPT 존재)
→ 각 작업에 대해 학습된 프롬프트와 분류 헤드만 저장하고 사전 훈련된 Transformer 모델의 원본을 재사용하여 저장 비용 크게 절감
』
📌 Experiments
본 논문에서는 다양한 규모의 사전 훈련된 Transformer 백본을 사용하여 광범위한 다운스트림 인식 작업에 대해 VPT를 평가하고자 함
[ 💡 Experiment Setup ]
( Pre-trained Backbones )
- Vision Transformers(ViT)
- Swin Transformers(Swin)
의 두 가지 Transformer 아키텍처를 실험
실험에서의 모든 백본은 ImageNet-21k에서 사전 훈련
분할된 이미지 패치 수, [CLS] 존재 여부 등은 원래 구성을 따름
( Baselines )
VPT의 두 변형(Shallow, Deep)을
일반적으로 사용되는 다른 미세 조정 프로토콜(아래의 프로토콜)과 비교
- Full : 모든 백본 및 분류 헤드 매개변수를 fully update
- classification head에 초점을 맞추어 update
- 선형 : 선형 레이어만 분류 헤드로 사용합니다.
- Partial-k : 다른 레이어를 동결하며 백본의 마지막 k개의 레이어를 미세 조정
- (백본과 분류 헤드의 경계 재정의)
- Mlp-k: 분류 헤드로 선형 레이어 대신 k 레이어가 있는 다층 퍼셉트론(MLP) 활용
- (사전 훈련된 백본을 튜닝 중 가중치가 고정되는 특징 추출기로 처리)
- 부분 집합 백본 매개변수를 update 혹은 새로운 훈련 가능한 매개변수를 백본에 추가하여 update
- Sidetune : 측면 네트워크를 훈련하고 사전 훈련된 기능과 측면 조정 기능 사이를 선형 보간한 후 네트워크에 입력
- Bias : 사전 훈련된 백본의 바이어스 항만 fine-tune
- Adapter : 변환기 레이어 내부에 residual connection이 있는 새 MLP 모듈을 삽입
( Downstream Tasks )
본 논문에서는 다음 두 가지 데이터 세트 컬렉션을 실험
FGVC
- CUB-200-201, NABirds, Oxford Flowers, Stanford Dogs 및 Stanford Cars를 포함한 5개의 벤치마킹된 Fine-Grained Visual Classification 작업으로 구성
- 특정 데이터 세트에 공개적으로 사용할 수 있는 학습 세트와 테스트 세트만 있는 경우, 이를 무작위로 training(90%)와 val(10%)로 나누고 val을 사용하여 하이퍼파라미터 선택
VTAB-1k
- 19개의 다양한 시각적 분류 작업 모음으로, 세 그룹으로 구성
- Natural - 표준 카메라를 사용하여 캡처한 자연스러운 이미지를 포함하는 작업;
- Specialized- 의료 및 위성 이미지와 같은 특수 장비를 통해 캡처한 이미지가 포함된 작업
- Structured - 객체 계산과 같은 기하학적 이해가 필요한 작업
- 1000개의 훈련 예제가 포함
- 제공된 훈련 세트의 800-200 분할을 사용하여 하이퍼 매개변수를 결정하고 전체 훈련 데이터를 사용하여 최종 평가를 실행
세 번의 실행 내에서 테스트 세트의 평균 정확도 점수를 제공
FGVC 데이터 세트의 평균 정확도와 VTAB의 세 그룹 각각의 평균 정확도를 제공

Scope : 조정 범위
Extra Params : 사전 훈련된 백본 및 linear head 외의 추가 매개변수의 존재 여부
Full을 제외한 모든 방법 중에서 가장 좋은 결과는 굵게 표시
VPT는 훈련 가능한 매개변수가 적은 24개 사례 중 20개 사례에서 전체 미세 조정을 능가함
[ 💡 Main Results ]
위 표는 VPT를 다른 7개 튜닝 프로토콜과 비교하여 4개의 다양한 다운스트림 작업 그룹에 걸쳐 평균적으로 사전 훈련된 ViT-B/16을 fine-tuning한 결과를 보여줌
이를 통해 아래와 같은 결론을 낼 수 있음
1. VPT-Deep은 4개 문제 클래스 중 3개(24개 작업 중 20개 작업)에서 Full보다 성능이 뛰어나며 전체 모델 매개변수는 훨씬 더 적게 사용(1.18× vs 24.02×)
→ 스토리지가 문제가 되지 않더라도 VPT는 비전에 더 큰 Transformer를 적용하기 위한 유망한 접근 방식임을 알 수 있음
이 결과는 NLP 분야의 연구와 대조됨 (프롬프트 tuning은 동일하게 사용하였으나 NLP에서는 성능이 더 좋게 나오진 않고 성능 대비 스토리지가 줄어드는 장점으로 연구됨)
2. VPT-Deep은 모든 작업 그룹에서 다른 모든 프로토콜보다 성능이 뛰어남
이는 VPTdeep이 저장 공간이 제한된 환경에서 최고의 미세 조정 전략임을 나타냄
3. VPT-deep보다 차선책이지만 VPT-shallow는 여전히 head 지향 튜닝 방법보다 적지 않은 성능 향상을 제공
이에 저장 제약이 심각한 경우 multi-task fine-tuned model을 배포하는 데 VPT-shallow가 가치 있는 선택임을 나타냄
( Performance comparison on different downstream data scales )

VPT-deep은 선형(왼쪽), 어댑터(가운데) 및 바이어스(오른쪽)와 비교됨
강조 표시된 영역은 VPT-deep과 비교된 방법 간의 정확도 차이를 보여줌
VPT-shallow의 결과는 쉽게 참조할 수 있도록 모든 플롯에 전체가 표시됨
마커의 크기는 조정 가능한 매개변수의 비율에 비례 (로그 스케일에서)
데이터 스케일 대비 전반적으로 좋은 성능을 보임
( VPT vs. Full across model scales (ViT-B, ViT-L and ViT-H) )
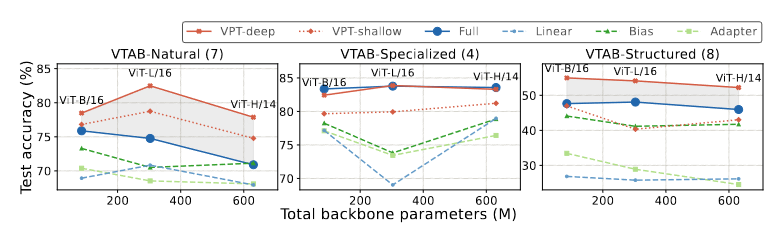
강조 표시된 영역은 VPT-deep과 전체 미세 조정(Full) 간의 정확도 차이를 보여줌
마커의 크기는 훈련 가능한 매개변수의 백분율에 비례 (로그 스케일에서)
+
different backbone scales, hierarchical Transformers에도 VPT에 대한 실험적 연구를 수행하였으며, 조금씩 차이는 있지만 VPT가 효과적임을 시사
[ 💡 Ablation on Model Design Variants ]
( 중요한 부분을 제거하여 제안한 요소가 모델에 어떠한 영향을 미치는지 확인하는 작업 )
감독된 ImageNet-21k 사전 훈련된 ViT-Base에서 다양한 모델 설계 선택을 제거하고 동일한 설정을 사용하여 VTAB에서 평가
( Prompt Lacation )
VPT와 다른 방법의 중요한 차이점은 Transformer 레이어에 대한 입력으로 도입된 추가 학습 가능한 매개변수임

위 그림은 입력 공간에 프롬프트를 삽입하는 방법과 위치, 최종 성능에 어떤 영향을 미칠지에 대한 다양한 선택을 제거해봄
상단 : 위치 설명
하단 : 결과
점선을 통해 기본 성능 시각화
prompt를 이미지 토큰의 channel에 추가하여 넣는 (concat-channel) 방법이나 prompt들을 하나로 channel-wise concat한 방법 (prepend-pixel)보다
prompt와 image를 element-wise 더한 방법 (add)나 prompt를 하나의 sequence로 넣는 방법 (prepending)이 더 좋은 결과를 보임
(그 중 prepending이 전반적으로 더 좋은 성능을 보여 이것을 default 모델로 잡음)
( Prompt Length )
전체 미세 조정과 비교하여 VPT 조정에 필요한 유일한 추가 하이퍼 매개변수

쉽게 참조할 수 있도록 개별 추가 하이퍼 매개변수(예: Mlp의 레이어 수 및 Adapter의 감소율)에 대한 두 가지 다른 기준도 제거
위 그래프에서 볼 수 있듯이 최적의 프롬프트 길이는 Task에 따라 다름
특히 단 하나의 프롬프트만으로도 VPT-deep은 여전히 다른 2개 기준보다 훨씬 뛰어난 성능을 발휘하며 VTABStructured 및 Natural의 전체 미세 조정에 비해 경쟁력을 유지하거나 훨씬 더 좋음
( Prompt Depth )

프롬프트를 삽입할 레이어와 수를 제거
VPT의 성능은 일반적으로 프롬프트 깊이와 양의 상관관계가 있음
그러나 프롬프트를 위에서 아래로 삽입(중간부터 들어오는 거)하면 정확도가 떨어짐
(이전 Transformer 레이어의 프롬프트가 이후 레이어의 프롬프트보다 더 중요하다는 것을 의미)
( Final Output )
ViT의 원래 구성에 따라 [CLS]의 최종 임베딩, 즉 Xn을 분류 헤드 입력으로 사용(ViT 실험의 기본 설정)

위 그림에서 볼 수 있듯이 이미지 패치 출력 임베딩 En에 대한 평균 풀링을 최종 출력(이미지 풀)으로 사용하면 결과는 기본적으로 동일하게 유지(VTAB-Specialized의 경우 82.4 vs 82.3)
그러나 풀링에 최종 프롬프트 출력 ZN(Prompt-pool 및 Global-pool)이 포함된 경우 정확도가 최대 8포인트까지 떨어질 수 있음
📌 Analysis and Discussion
[ 💡 Visualization ]

위 그림은 Xn의 t-SNE 시각화, 즉 VTAB의 각 하급 집단을 보임
모든 플롯은 VPT-deep이 Full보다 적은 매개변수를 사용하면서 선형 분리 가능한 표현을 가능하게 함을 보여줌
또한 모든 Transformer 레이어(VPT-deep)에 대한 추가 조정 가능한 매개변수가 첫 번째 레이어의 입력에 대한 프롬프트만 삽입하는 VPT-shallow에 비해 성능을 향상시키는 것을 관찰함
흥미롭게도 Clevr/count에서 VPT-deep 및 Full은 VPT-shallow 및 Linear와 달리 작업의 기본 다양한 구조(이미지 대 거리 번호 또는 풍경 인식의 객체 계산)를 복구함
[ 💡 Apply VPT to more vision tasks ]
[ 💡 Apply VPT to more pre-training methods ]
[ 💡 Apply VPT to ConvNets ]
(VPT에 대한 추가적인 고찰 : 생략)
📌 Conclusion
광범위한 다운스트림 작업에 대형 비전 Transformer 모델을 활용하는 새로운 매개변수 효율적인 접근 방식인 VPT를 소개함
VPT는 사전 학습된 백본을 고정된 상태로 유지하면서 입력 공간에 작업별 학습 가능한 프롬프트를 도입
본 논문에서는 VPT가 다른 fint-tuning 프로토콜(종종 전체 미세 조정 포함)을 능가하는 동시에 스토리지 비용을 크게 줄일 수 있음을 보여줌
본 실험은 또한 다양한 사전 훈련 목표를 가진 비전 트랜스포머의 fine-tuning과 효율적인 방식으로 더 광범위한 비전 인식 작업으로 전환하는 방법에 대한 흥미로운 질문을 제기함
📌 느낀 점
Foundation Model의 확장을 다루기보다는 CV 분야에서의 이미 큰 모델을 사람들이 사용할 때 downstream 작업을 고려하며 시작된 논문임
목적이 명확하며, 사전의 다른 분야에서의 연구들에 영감을 받아 이를 도입한 적절한 방법론을 제시하고 이를 연구한 흐름이 읽기에도 편하고 재미있게 느껴짐
또한 CLIP, CoOp, CoCoOp을 접하며 ‘Prompt를 학습하는 모델’에 대한 프롬프트의 개념이 자연어 프롬프트의 개념과 섞여 살짝 헷갈렸는데, 본 논문을 읽으며 모델이 학습해나갈 downstream task에 대한 방향성임을 깨달을 수 있었음